Các doanh nghiệp hàng ngày phải xử lý hàng triệu tài liệu, từ hồ sơ bảo hiểm, hóa đơn đến hợp đồng pháp lý. Các giải pháp nhận dạng ký tự quang học (OCR) truyền thống chỉ có thể trích xuất văn bản thô, không hiểu được ngữ cảnh hay mối quan hệ giữa các dữ liệu. Hạn chế này tạo ra các nút thắt cổ chai, đòi hỏi sự can thiệp thủ công, làm tăng thời gian, chi phí và nguy cơ sai sót.
Để giải quyết thách thức này, AWS đã giới thiệu một kiến trúc pipeline xử lý tài liệu thông minh, kết hợp sức mạnh của AI tạo sinh trên nền tảng Amazon Bedrock. Giải pháp này giúp tự động hóa việc trích xuất và phân tích insight từ các tài liệu phức tạp, bao gồm cả biểu đồ và đồ thị, giúp doanh nghiệp biến quy trình xử lý tài liệu từ một trung tâm chi phí thành một tài sản chiến lược.
Tổng quan giải pháp xử lý tài liệu thông minh của AWS
Pipeline xử lý tài liệu thông minh của AWS kết hợp AI tạo sinh với các luồng công việc được điều phối để tự động trích xuất, phân tích các yếu tố trực quan (biểu đồ, đồ thị) và rút ra insight từ tài liệu, đồng thời duy trì ngữ cảnh và mối quan hệ giữa nhiều nguồn dữ liệu. Giải pháp này xử lý tài liệu qua bốn lớp tích hợp:
- Lớp xử lý đầu vào (Input processing): Tiếp nhận và điều hướng tài liệu đầu vào.
- Lớp trích xuất và lưu trữ (Extraction and storage): Trích xuất văn bản thô, bảng biểu, phân tích hình ảnh và tích hợp dữ liệu.
- Lớp trí tuệ (Intelligence): Xây dựng cơ sở tri thức với tìm kiếm ngữ nghĩa và phân tích bằng các mô hình nền tảng đa phương thức (multimodal foundation model).
- Lớp điều phối agent (Agentic coordination): Sử dụng một agent điều phối và các agent chuyên trách cho từng tác vụ cụ thể.
Kiến trúc và các thành phần chính
Kiến trúc tổng thể của giải pháp được thiết kế để xử lý tài liệu một cách liền mạch từ đầu đến cuối.
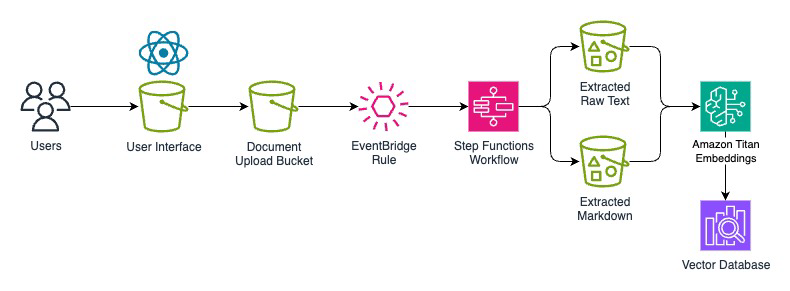
Lớp xử lý đầu vào
Lớp này quản lý việc tiếp nhận và định tuyến ban đầu cho các tài liệu đến. Khi tài liệu được tải lên các bucket Amazon S3, luồng xử lý sẽ được kích hoạt. Dịch vụ Amazon Bedrock Data Automation (BDA) đóng vai trò là công cụ trích xuất cốt lõi, xử lý việc phân chia, phân loại và trích xuất nội dung tài liệu thông qua một API hợp nhất. AWS Step Functions điều phối toàn bộ luồng công việc, mang lại khả năng giám sát và kiểm soát hoạt động.
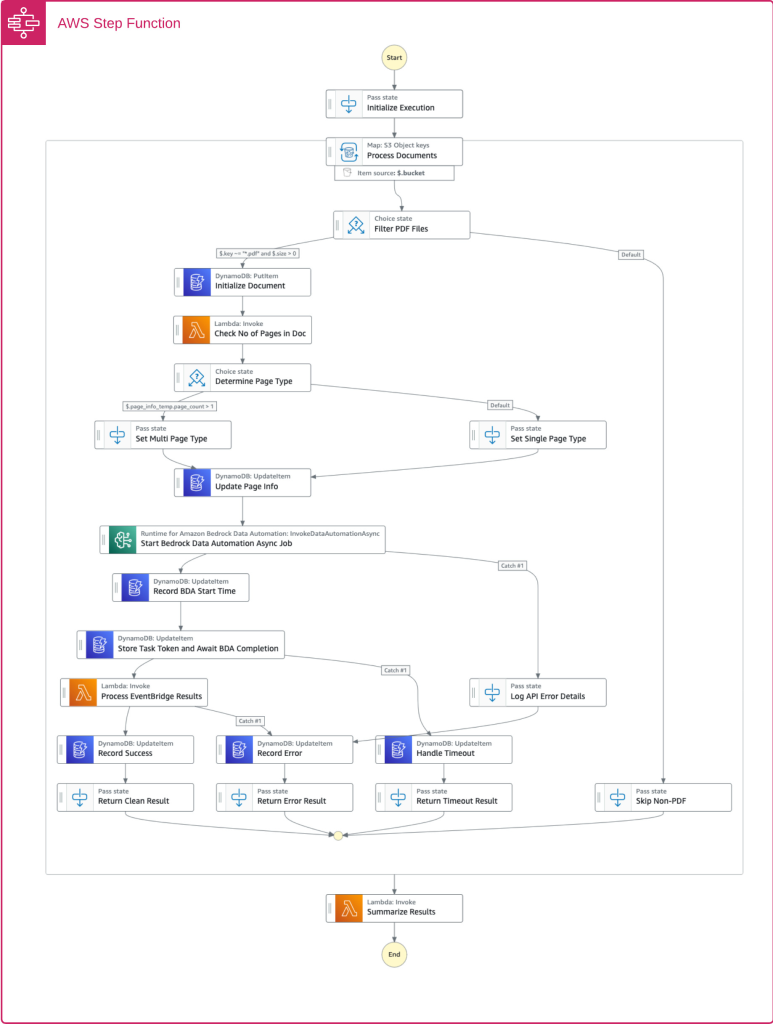
Luồng điều phối chi tiết bao gồm:
- Tiếp nhận tài liệu: Các tệp với nhiều định dạng khác nhau được đưa vào S3 và xử lý qua API hợp nhất.
- Ghi nhận metadata: Luồng công việc ghi lại metadata của tài liệu trong Amazon DynamoDB để theo dõi và kiểm toán.
- Phân tích số trang: Luồng công việc kiểm tra số trang để tối ưu hóa chiến lược xử lý. BDA có thể tự động xử lý các tài liệu lên đến 3.000 trang.
- Gọi xử lý BDA: Luồng công việc khởi chạy một tác vụ BDA bất đồng bộ. BDA sẽ tự động phân chia, phân loại, khớp tài liệu với các blueprint (bản thiết kế) phù hợp và trích xuất toàn bộ nội dung.
- Xử lý bất đồng bộ: Luồng công việc chờ đợi tác vụ BDA hoàn thành, cho phép xử lý hàng nghìn tài liệu đồng thời.
- Xử lý lỗi: Hệ thống quản lý các kịch bản lỗi khác nhau để đảm bảo không tài liệu nào bị mất.
Lớp trích xuất và lưu trữ
Đây là lớp trung tâm của giải pháp, nơi Amazon Bedrock Data Automation (BDA) biến nội dung thô thành dữ liệu có cấu trúc và hữu ích. BDA cung cấp hai tùy chọn đầu ra linh hoạt:
- Đầu ra tiêu chuẩn: Cung cấp thông tin thường dùng như tóm tắt tài liệu, văn bản đã trích xuất, chú thích bảng biểu và các insight do AI tạo ra.
- Đầu ra tùy chỉnh với Blueprints: Blueprints là các bản thiết kế được cấu hình sẵn để xác định logic trích xuất cho từng loại tài liệu cụ thể. Ví dụ, một blueprint cho hóa đơn và một blueprint khác cho báo cáo tài chính. BDA có thể tự động khớp tài liệu với blueprint phù hợp, cho phép xử lý nhiều loại tài liệu đa dạng trong một luồng công việc duy nhất.
Ngoài ra, BDA còn có khả năng phân tích hình ảnh, trích xuất insight từ các biểu đồ, đồ thị mà các giải pháp OCR truyền thống không thể diễn giải được.
Lớp trí tuệ
Lớp này là bộ não nhận thức của giải pháp. Amazon Bedrock Knowledge Bases được cấu hình để hoạt động với Amazon OpenSearch Serverless, biến nội dung thô thành insight thông qua tìm kiếm ngữ nghĩa và kỹ thuật Retrieval Augmented Generation (RAG). Các mô hình nền tảng (FM) trên Amazon Bedrock sẽ phân tích nội dung trực quan, diễn giải biểu đồ và phát hiện các mối quan hệ giữa văn bản và hình ảnh.
Lớp điều phối Agent
Lớp này tổ chức trí thông minh của giải pháp. Strands Agents trên Amazon Bedrock AgentCore Runtime quản lý luồng xử lý tổng thể bằng cách định tuyến các yêu cầu đến các agent chuyên trách phù hợp.
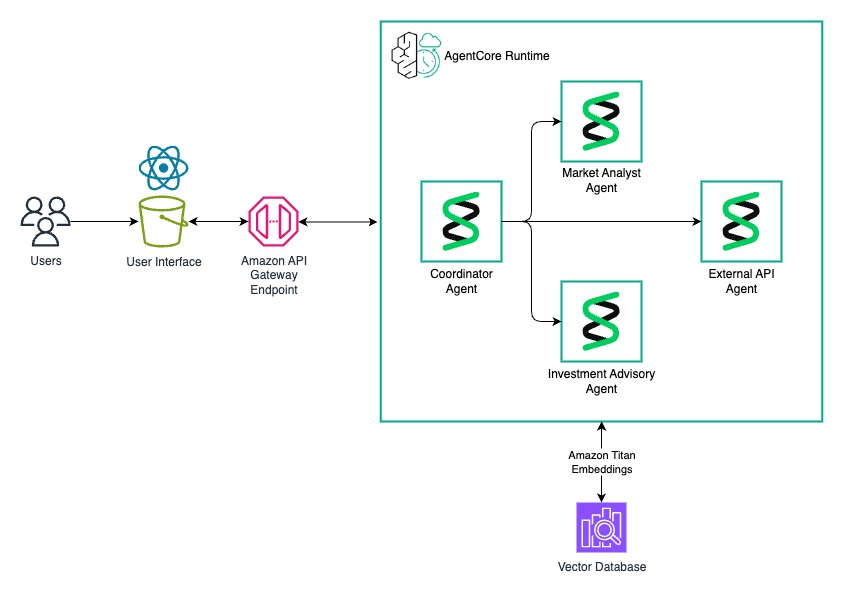
Các agent chuyên trách xử lý các chức năng cụ thể:
- Agent phân tích thị trường: Xử lý báo cáo thị trường tài chính và tài liệu đầu tư.
- Agent tư vấn đầu tư: Phân tích danh mục đầu tư và tài liệu tư vấn.
- Agent API bên ngoài: Tích hợp dữ liệu thời gian thực từ các nhà cung cấp dữ liệu tài chính.
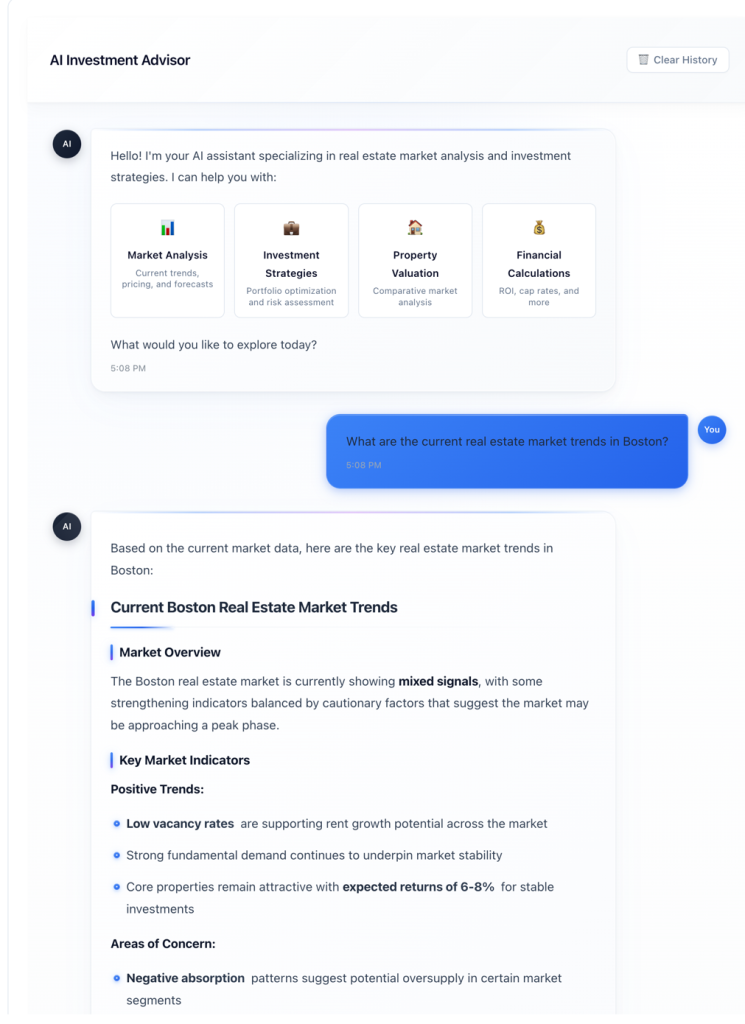
Trường hợp sử dụng: Phân tích bất động sản thương mại
Một công ty đầu tư bất động sản thương mại nhận hơn 200 báo cáo thẩm định tài sản mỗi tháng. Các báo cáo này chứa nhiều loại tài liệu phức tạp: tổng quan tài sản, bảng phân tích tài chính, biểu đồ so sánh thị trường, hình ảnh và tài liệu pháp lý.

Triển khai
Giải pháp của AWS đã thay đổi cách công ty này phân tích đầu tư bất động sản:
- Phân loại tài liệu: Hệ thống tự động xác định loại tài liệu và định tuyến đến các agent xử lý phù hợp.
- Trích xuất nội dung đa phương thức: Các agent phân tích biểu đồ tài chính, hình ảnh bất động sản và đối chiếu dữ liệu giữa các tài liệu để xác thực dòng tiền dự kiến.
- Truy vấn bằng ngôn ngữ tự nhiên: Các chuyên gia đầu tư có thể đặt câu hỏi bằng ngôn ngữ tự nhiên, ví dụ: “Hiển thị các tài sản có IRR dự kiến trên 12%” hoặc “So sánh dự báo tăng trưởng NOI với hiệu suất thị trường thực tế cho các tài sản tương tự.”
Kết quả
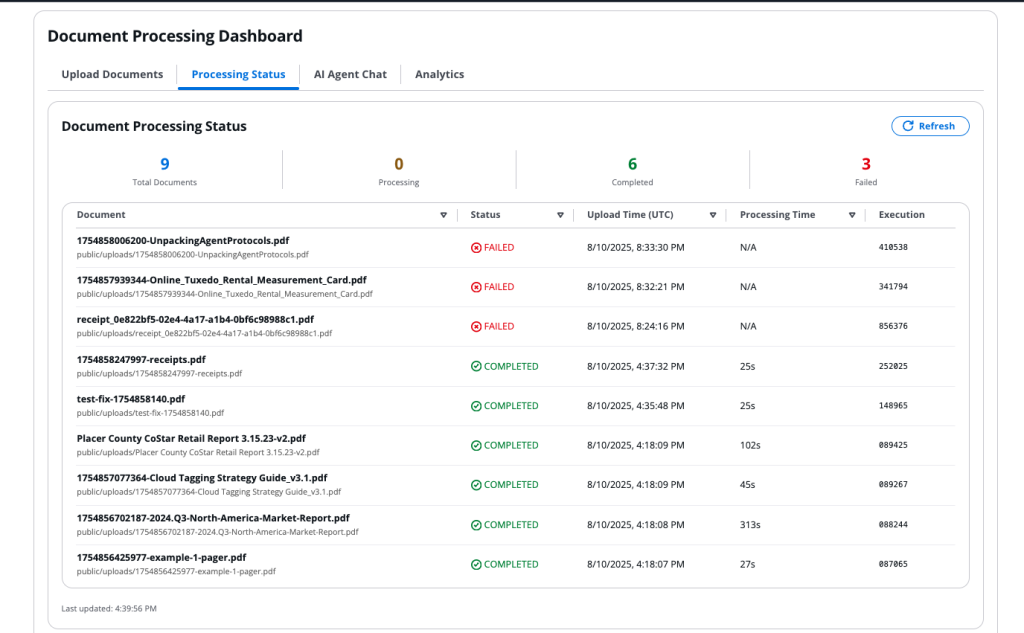
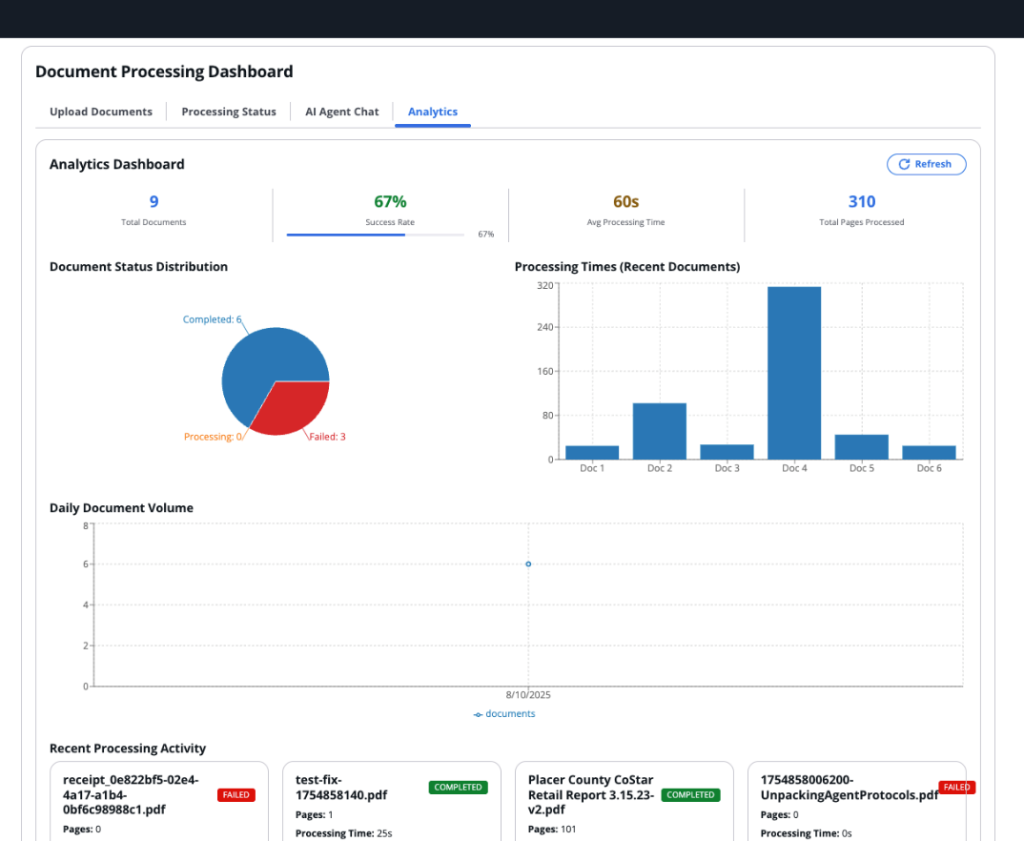
Thời gian xử lý sàng lọc ban đầu cho mỗi tài sản giảm từ 3-4 giờ xuống còn 15-20 phút. Việc trích xuất tự động giúp loại bỏ lỗi nhập liệu thủ công, trong khi việc xác thực chéo giữa các tài liệu giúp phát hiện sự không nhất quán. Công ty có thể xử lý nhiều cơ hội hơn đáng kể và xác định các khoản đầu tư hấp dẫn mà trước đây có thể đã bị bỏ qua. Giải pháp đã được kiểm chứng về khả năng mở rộng, xử lý thành công hơn 50.000 tài liệu PDF đồng thời mà không bị suy giảm hiệu năng.
Triển khai và tối ưu chi phí
AWS cung cấp mã nguồn triển khai hoàn chỉnh thông qua AWS Cloud Development Kit (AWS CDK) trên kho lưu trữ GitHub công khai, cho phép doanh nghiệp thiết lập toàn bộ kiến trúc bằng phương pháp hạ tầng dưới dạng mã (IaC).
Để quản lý chi phí vận hành hiệu quả, AWS đề xuất các chiến lược sau:
- Định tuyến thông minh: Định tuyến tài liệu đến các cấp độ xử lý phù hợp dựa trên độ phức tạp.
- Xử lý theo lô (Batch processing): Nhóm nhiều tài liệu vào một yêu cầu BDA duy nhất để giảm chi phí.
- Quản lý vòng đời lưu trữ: Sử dụng chính sách vòng đời của Amazon S3 để tự động chuyển các tài liệu đã xử lý sang các tầng lưu trữ chi phí thấp hơn.
Kiến trúc này cũng tích hợp các biện pháp bảo mật cấp doanh nghiệp như mã hóa bằng AWS KMS, kết nối an toàn qua AWS PrivateLink và vai trò IAM với nguyên tắc cấp quyền tối thiểu.
Bằng cách tự động hóa việc trích xuất và phân tích insight từ tài liệu, bao gồm cả các yếu tố trực quan phức tạp, doanh nghiệp có thể khai phá giá trị bị khóa trong nội dung phi cấu trúc, đưa ra quyết định nhanh hơn và đạt được lợi thế cạnh tranh.