Việc xây dựng các voice agent (agent AI bằng giọng nói) có khả năng mở rộng, mang lại trải nghiệm tự nhiên và đáng tin cậy là một ưu tiên lớn của nhiều doanh nghiệp. Tuy nhiên, các đội ngũ phát triển thường đối mặt với thách thức về độ trễ cao, quản lý âm thanh thời gian thực và phối hợp nhiều agent trong các quy trình phức tạp.
Trong một bài đăng vào ngày 19/05/2026, AWS đã chia sẻ các mẫu kiến trúc để giải quyết những thách thức này. Bằng cách sử dụng Amazon Nova Sonic, Amazon Bedrock AgentCore và framework mã nguồn mở Strands, doanh nghiệp có thể xây dựng các voice agent co giãn, dễ bảo trì, giúp tạo ra các tương tác với khách hàng thông minh và phản hồi nhanh hơn.
Các thành phần chính
Để xây dựng giải pháp, AWS đề xuất kết hợp ba thành phần công nghệ chính.
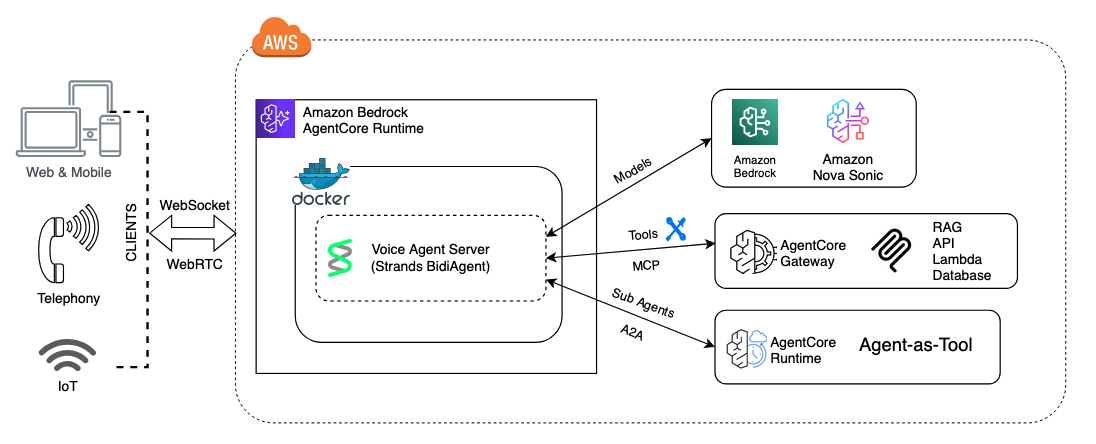
- Amazon Nova Sonic: Là một mô hình nền tảng (foundation model) tạo ra các cuộc hội thoại giọng nói-sang-giọng nói tự nhiên, giống người cho các ứng dụng AI tạo sinh. Người dùng có thể tương tác với AI qua giọng nói trong thời gian thực, với khả năng hiểu ngữ điệu và thực hiện hành động.
- Amazon Bedrock AgentCore Runtime: Môi trường hosting phi máy chủ (serverless) dành cho các agent AI. Doanh nghiệp có thể đóng gói agent dưới dạng container, triển khai lên AgentCore Runtime để nền tảng tự động xử lý việc co giãn, cách ly phiên và thanh toán. Đối với voice agent, dịch vụ này cung cấp bidirectional WebSocket streaming (truyền phát hai chiều), cách ly phiên ở cấp độ microVM để tránh nhiễu và tăng đột biến độ trễ, cùng với các chỉ số đo lường chuyên biệt cho giọng nói.
- Strands Agents: Một framework mã nguồn mở để xây dựng agent AI. Lớp
BidiAgentcủa nó là một tùy chọn tích hợp giữa Nova Sonic và ứng dụng của bạn, giúp đơn giản hóa việc quản lý vòng đời của luồng hai chiều, định tuyến các lệnh gọi công cụ (tool) và quản lý phiên.
Ba mẫu kiến trúc tích hợp cho voice agent
Thay vì xây dựng một agent toàn năng, các hệ thống giọng nói hiện đại thường được cấu thành từ các agent chuyên dụng, sử dụng công cụ (tool) hoặc các sub-agent (agent phụ), kết hợp với chiến lược session segmentation (phân đoạn phiên) để cô lập prompt, bộ nhớ và quyền truy cập. Các mẫu này cho phép doanh nghiệp phân tách các trợ lý lớn thành những thành phần nhỏ hơn, chuyên biệt và có thể tái sử dụng.
Mẫu 1: AgentCore Gateway – Chọn công cụ với độ trễ thấp
Trong mẫu này, logic nghiệp vụ hiện có của bạn được hiển thị dưới dạng các công cụ (tool) – các hàm riêng biệt mà Amazon Nova Sonic có thể gọi trực tiếp trong cuộc hội thoại. Mô hình giọng nói sẽ tự quyết định công cụ nào cần gọi, truyền tham số, nhận kết quả và phản hồi lại bằng giọng nói. Không có lớp suy luận trung gian giữa mô hình và công cụ, giúp giảm thiểu độ trễ.
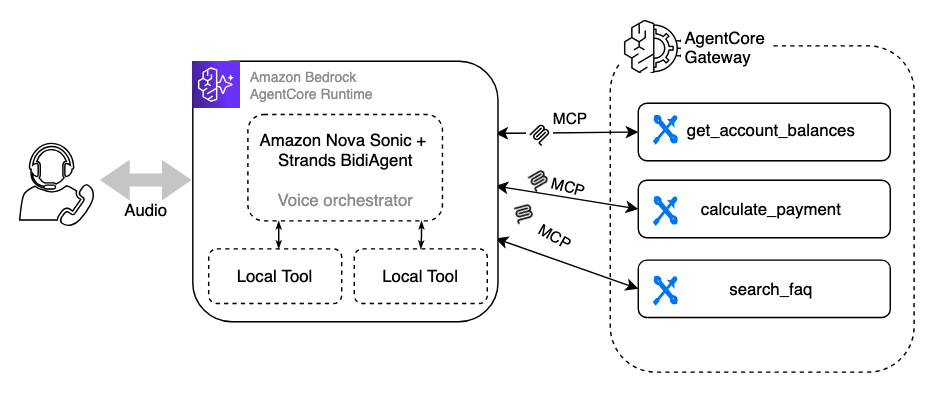
Ví dụ, khi người dùng hỏi “Số dư tài khoản của tôi là bao nhiêu?”, Nova Sonic sẽ hiểu ý định, chọn công cụ get_account_balance, gọi công cụ với tham số phù hợp và đọc kết quả trả về.
Đánh đổi: Mọi quyết định đều do Nova Sonic thực hiện. Nếu một lệnh gọi công cụ đòi hỏi logic phức tạp như xác thực nhiều bước hoặc chuỗi nhiều hoạt động, gánh nặng suy luận này hoàn toàn thuộc về system prompt của mô hình giọng nói. Điều này phù hợp với các công cụ đơn giản nhưng có thể trở nên kém ổn định với các quy trình phức tạp.
Mẫu 2: Sub-agent – Tăng cường suy luận với agent độc lập
Với mẫu sub-agent, logic nghiệp vụ của bạn chạy trong các agent tự trị, mỗi agent có mô hình, system prompt, công cụ và khả năng suy luận riêng. Agent điều phối chính (voice orchestrator) sẽ ủy thác toàn bộ tác vụ cho các sub-agent này thay vì gọi từng công cụ riêng lẻ.
Có hai cách tiếp cận phổ biến để kết nối:
- Local agent-as-tool: Sub-agent chạy trong cùng tiến trình, được gói lại như một hàm
@tool. Cách này đơn giản nhất, không có độ trễ mạng nhưng sub-agent sẽ chia sẻ tài nguyên và co giãn cùng với agent điều phối. - Remote agent qua giao thức A2A: Sub-agent được triển khai như một máy chủ độc lập trên AgentCore Runtime và được gọi qua mạng bằng giao thức mở A2A (Agent-to-Agent). Điều này cho phép các agent được xây dựng bằng các framework khác nhau (Strands, LangGraph, OpenAI) có thể giao tiếp và chia sẻ ngữ cảnh.
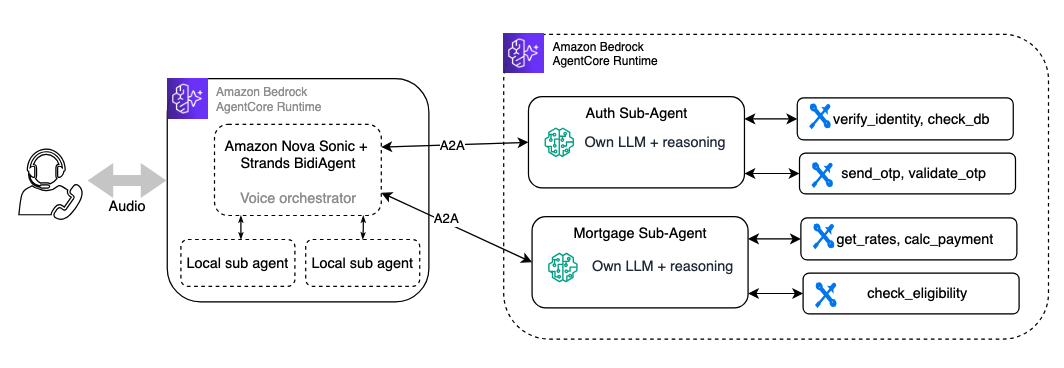
Đánh đổi: Mỗi lệnh gọi sub-agent sẽ làm tăng độ trễ do cần thêm thời gian cho mô hình của sub-agent suy luận và thực thi công cụ. Trong hội thoại bằng giọng nói, điều này có thể tạo ra những khoảng lặng không mong muốn.
Mẫu 3: Phân đoạn phiên (Session Segmentation) – Tối ưu độ trễ
Đây là một phương pháp được thiết kế đặc biệt cho các kịch bản giọng nói nơi độ trễ là yếu tố quan trọng nhất. Thay vì ủy thác cho các công cụ hoặc sub-agent bên ngoài, bạn phân đoạn cuộc hội thoại thành các giai đoạn logic, mỗi giai đoạn có phiên Nova Sonic, system prompt và bộ công cụ riêng.
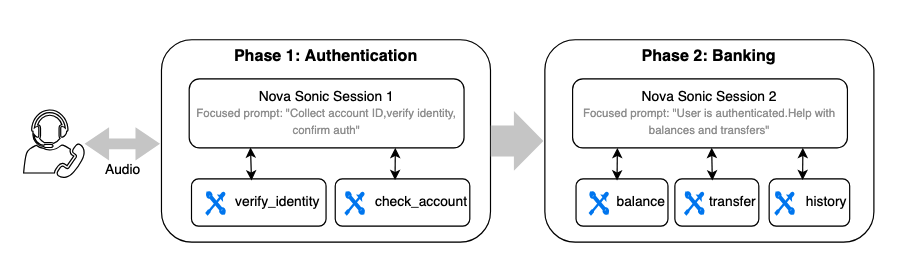
Ví dụ, một trợ lý ảo ngân hàng có thể có ba giai đoạn: xác thực, quản lý tài khoản và tư vấn thế chấp. Mỗi giai đoạn sẽ chạy một phiên Nova Sonic riêng biệt với:
- System prompt tập trung: Ngắn gọn, cụ thể, giảm khả năng mô hình bị nhầm lẫn.
- Chỉ các công cụ liên quan: Mô hình không lãng phí chu kỳ suy luận để lựa chọn giữa 15 công cụ khi chỉ cần 3.
Ngữ cảnh của phiên trước có thể được chuyển sang phiên mới dưới dạng lịch sử trò chuyện, đảm bảo tính liên tục của toàn bộ cuộc hội thoại.
Các phương pháp tối ưu độ trễ cho voice agent
Độ trễ là yếu tố then chốt khi xây dựng voice agent. Dưới đây là các kỹ thuật thực tế để giữ cho thời gian phản hồi luôn nhanh chóng:
- Bắt đầu với các mô hình nhỏ cho sub-agent: Sử dụng các mô hình như Amazon Nova 2 Lite hoặc Nova 2 Micro cho các sub-agent chuyên dụng. Chúng nhanh, tối ưu chi phí và xử lý tốt hầu hết các tác vụ.
- Thiết kế sub-agent có trạng thái với caching: Thay vì truy vấn cơ sở dữ liệu hoặc API mỗi lần, hãy thiết kế sub-agent để lưu trữ (cache) kết quả trong một phiên làm việc.
- Tải trước dữ liệu (prefetch) sau khi xác thực: Trong các kịch bản tổng đài, sau khi khách hàng xác thực, hãy ngay lập tức tìm nạp dữ liệu tài khoản của họ ở chế độ nền. Khi khách hàng hỏi, câu trả lời đã có sẵn trong bộ nhớ.
- Thực thi song song các lệnh gọi công cụ độc lập: Nếu người dùng yêu cầu tổng quan về nhiều tài khoản, hãy thực hiện các lệnh gọi API đồng thời thay vì tuần tự.
- Sử dụng các câu nói đệm: Khi một lệnh gọi công cụ hoặc sub-agent là không thể tránh khỏi, hãy hướng dẫn mô hình giọng nói nói một câu đệm ngắn như “Để tôi kiểm tra giúp bạn…” để tránh khoảng lặng.
- Giảm thiểu số lượng công cụ mỗi phiên: Nếu một agent có 15 công cụ nhưng một cuộc hội thoại thông thường chỉ sử dụng 3-4, hãy xem xét mẫu phân đoạn phiên để chỉ tải các công cụ cần thiết cho mỗi giai đoạn.