Các mô hình ngôn ngữ lớn (LLM) hiện nay thường gặp khó khăn khi phải phân tích các tài liệu khổng lồ dài hàng triệu ký tự, do bị giới hạn bởi “cửa sổ ngữ cảnh” (context window). Mới đây, AWS đã giới thiệu một phương pháp đột phá sử dụng Recursive Language Models (RLM) trên nền tảng Amazon Bedrock AgentCore, cho phép các agent AI xử lý và suy luận trên các tài liệu với dung lượng không giới hạn, mở ra tiềm năng ứng dụng to lớn cho doanh nghiệp.
Thách thức từ giới hạn của Context Window
Khi doanh nghiệp cần phân tích các tài liệu phức tạp như báo cáo tài chính thường niên dài hàng trăm trang, hồ sơ pháp lý, hay tài liệu nghiên cứu khoa học, họ thường vấp phải rào cản về context window của LLM. Nếu đưa toàn bộ tài liệu vào, mô hình sẽ từ chối xử lý hoặc đưa ra câu trả lời dựa trên thông tin không đầy đủ.
Ngay cả với các mô hình có context window lớn, chúng vẫn có thể gặp phải vấn đề “lost in the middle” – tức là khó chú ý đến các thông tin nằm ở giữa một văn bản dài. Đây là một giới hạn cố hữu mà chỉ kỹ thuật prompt engineering không thể giải quyết triệt để. Doanh nghiệp cần một cách tiếp cận tách biệt hoàn toàn dung lượng tài liệu khỏi context window của mô hình.
Mô hình Ngôn ngữ Đệ quy (RLM): Một hướng tiếp cận mới
Phương pháp Recursive Language Models (RLM), hay Mô hình Ngôn ngữ Đệ quy, thay đổi hoàn toàn cách tiếp cận vấn đề. Thay vì nạp toàn bộ tài liệu vào context window, RLM xem tài liệu đầu vào như một môi trường bên ngoài mà mô hình có thể tương tác một cách có lập trình.
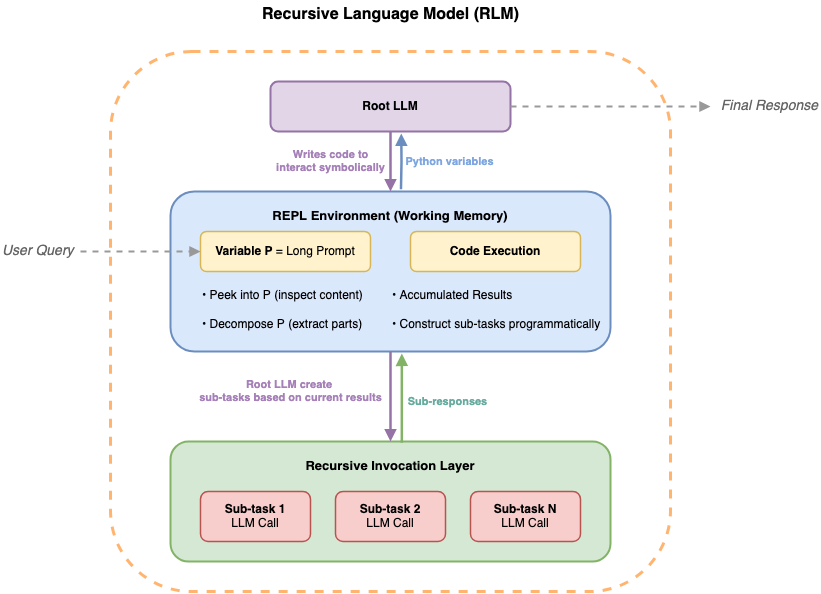
Một LLM gốc (root LLM) sẽ điều phối toàn bộ quá trình. Nó nhận yêu cầu của người dùng, sau đó tự viết mã để tìm kiếm, cắt lát và phân tích tài liệu theo từng bước. Khi cần hiểu sâu một phần cụ thể, nó sẽ ủy thác nhiệm vụ cho một LLM phụ (sub-LLM). Kết quả phân tích của sub-LLM được lưu trữ trong bộ nhớ đệm dưới dạng biến Python, thay vì chiếm dụng không gian trong context window của LLM gốc. Cấu trúc đệ quy này cho phép mô hình xử lý các tài liệu có độ dài bất kỳ.
Kiến trúc trên Amazon Bedrock AgentCore
AWS đã hiện thực hóa kiến trúc RLM bằng cách kết hợp Amazon Bedrock AgentCore Code Interpreter và Strands Agents SDK. Kiến trúc này gồm ba thành phần chính:
- Root LLM agent: Xây dựng bằng Strands Agents SDK, nhận yêu cầu và quyết định đoạn mã Python nào cần thực thi.
- Bedrock AgentCore Code Interpreter: Cung cấp một môi trường Python sandbox an toàn, hoạt động như một bộ nhớ làm việc (working memory) bền bỉ. Toàn bộ tài liệu được tải vào môi trường này.
- Hàm
llm_query(): Cho phép agent gọi trực tiếp các sub-LLM của Amazon Bedrock từ bên trong môi trường sandbox, giữ cho kết quả phân tích cục bộ và không làm đầy context window của root LLM.

Nhờ chế độ mạng PUBLIC của Code Interpreter, môi trường sandbox có thể thực hiện các lệnh gọi API ra bên ngoài tới Amazon Bedrock. Trạng thái phiên làm việc được duy trì liên tục, cho phép các kết quả trung gian được tích lũy, tạo ra một bộ nhớ làm việc hiệu quả cho mô hình trong suốt quá trình phân tích.
Hiệu quả vượt trội đã được kiểm chứng
Hiệu quả của phương pháp RLM đã được AWS đánh giá trên bộ benchmark LongBench v2, được thiết kế để kiểm tra khả năng suy luận của LLM trên các ngữ cảnh dài.
Kết quả cho thấy ba điểm chính:
- Độ tin cậy 100%: Các phương pháp truyền thống thường thất bại khi tài liệu quá lớn. Ngược lại, RLM đạt tỷ lệ xử lý thành công 100% trên tất cả các thử nghiệm, vì nó đã loại bỏ hoàn toàn sự phụ thuộc vào kích thước context window.
- Cải thiện độ chính xác đáng kể: Trên tác vụ hỏi đáp tài chính, RLM giúp độ chính xác của mô hình Claude Opus 4.6 tăng từ 66.7% lên 80.0%. Trên tác vụ phân tích mã nguồn, độ chính xác của Claude Sonnet 4.5 tăng vọt từ 20.0% lên 76.0%. Điều này cho thấy RLM không chỉ xử lý được nhiều dữ liệu hơn mà còn giúp mô hình suy luận tốt hơn.
- Tối ưu chi phí: Nghiên cứu cũng chỉ ra rằng việc sử dụng một sub-LLM nhỏ hơn và tiết kiệm chi phí hơn (như Claude Haiku 4.5) không ảnh hưởng đáng kể đến độ chính xác cuối cùng. Điều này cho phép doanh nghiệp cân bằng giữa hiệu năng và chi phí khi triển khai.
Lưu ý cho doanh nghiệp
Khi áp dụng RLM, doanh nghiệp cần cân nhắc một vài yếu tố:
- Độ trễ: RLM đánh đổi độ trễ để lấy năng lực xử lý. Phương pháp này phù hợp nhất cho các tác vụ phân tích offline hoặc xử lý theo lô, nơi thời gian phản hồi không phải là ưu tiên hàng đầu.
- Cost: Mỗi tác vụ RLM bao gồm nhiều lệnh gọi mô hình. Doanh nghiệp có thể tối ưu chi phí bằng cách sử dụng một mô hình lớn, mạnh mẽ làm root LLM và một mô hình nhỏ hơn, nhanh hơn làm sub-LLM.
- Prompt Engineering: Vai trò của prompt vẫn rất quan trọng để hướng dẫn mô hình sử dụng các công cụ một cách hiệu quả, giảm thiểu các lệnh gọi không cần thiết và cải thiện độ trễ.
Bằng cách kết hợp Amazon Bedrock AgentCore Code Interpreter với phương pháp RLM, các doanh nghiệp giờ đây đã có một công cụ mạnh mẽ để khai phá thông tin từ những bộ dữ liệu văn bản lớn nhất, từ phân tích tài chính, rà soát pháp lý, nghiên cứu khoa học đến kiểm toán tuân thủ.